
Inclusion of reasoning "chains of idea" (CoT) in the model output substantially improves its quality, however it increases reasoning expense.
- Distillation transfers reasoning understanding from a costly teacher model to a more affordable trainee, minimizing overall inference cost.
- DeepSeek R1 can produce detailed CoT, making it an outstanding teacher model.
- Synthetic information produced by DeepSeek R1 might exceed information produced by human experts.
Introduction
The recent release of DeepSeek R1 has taken the AI community by storm, providing efficiency on par with leading frontier models-such as OpenAI's o1-at a portion of the expense. Still, R1 can be costly for usage cases with high traffic or low latency requirements.
DeepSeek R1's strength lies in its explicit detailed reasoning. Before generating a final response, it creates an internal "chain of idea" (CoT) to systematically reason through each issue. This process is a kind of test-time calculation, permitting the model to dynamically designate more compute to complex problems. However, these extended reasoning sequences typically increase reasoning expense.
Distillation
Distillation is a method for transferring understanding from a large, more effective teacher design to a smaller, more economical trainee model. According to the DeepSeek R1 paper, R1 is extremely effective in this teacher function. Its detailed CoT sequences assist the trainee model to break down complex tasks into smaller sized, more manageable steps.
Comparing Distillation to Human-Labeled Data
Although fine-tuning with human-labeled information can produce specific designs, collecting both final answers and their corresponding thinking steps is pricey. Distillation scales more easily: instead of counting on human annotations, the instructor model immediately produces the training data for the trainee.
A Side Note on Terminology
The term "distillation" can refer to various methods:
Distribution Distillation Aligns the trainee design's output token circulation with the teacher's using Kullback-Leibler divergence (KL-divergence).
Works finest when both designs share the same architecture, tokenizer, and pre-training data.

Data Distillation Uses the instructor design to create completions for a set of triggers.
Fine-tunes the trainee model using a basic cross-entropy loss on these produced outputs, skipping the KL-divergence term.
Allows the instructor and trainee to be different model families and tokenizers (though if the instructor utilizes specialized tokens like __, it can be helpful for both designs to recognize them).
In this post, we concentrate on the data distillation because it supports a larger range of student-teacher pairs.
Data Generation

Training data is often a traffic jam in design advancement. In a recent post (add link), we checked out how to create labels by combining model output with a confirmation function. Distillation takes a various approach, using an instructor design to manufacture missing out on conclusions.
DeepSeek R1 sticks out due to the fact that it not only offers last responses however also exposes its detailed chain of thought-unlike other thinking models that keep this internal procedure hidden. If your dataset consists of ground fact answers, you can determine top quality artificial CoTs through rejection sampling, selecting only the best chains to additional improve your fine-tuned design. Rejection tasting can remove inaccurate information examples either by comparing the created information against ground fact labels or by using a user-defined validation function. From the user interface perspective, the validation function resembles the proven reward function used by value-model-free RL approaches like these explained in our recent post.
Case Study: GSM8K
.png)
GSM8K (Grade School Math 8K) is a dataset of 8.5 K varied grade-school mathematics word issues. Each information point consists of:
1. A problem description.
2. A human expert's chain of idea.
3. The final answer.
.webp)
We broadened this dataset by including:
Synthetic R1 reasoning, surgiteams.com i.e., the CoT generated by DeepSeek R1.
Then, we fine-tuned 3 versions of the design (using LoRA on llama-3.1 -8 B-instruct), each with different training targets:
Direct Answer Only: Generate the final answer without showing reasoning.
Human Expert CoT: Generate the final response together with a reasoning chain looking like the human professional's.
Synthetic R1 CoT: Generate the final response together with DeepSeek R1's synthetic reasoning chain.
The table listed below summarizes average accuracy and thinking length:

- Note: The accuracy for the 5-shot baseline might differ from numbers reported elsewhere due to different evaluation setups. The crucial focus is on comparing relative efficiency throughout distillation approaches, not on beating other designs.
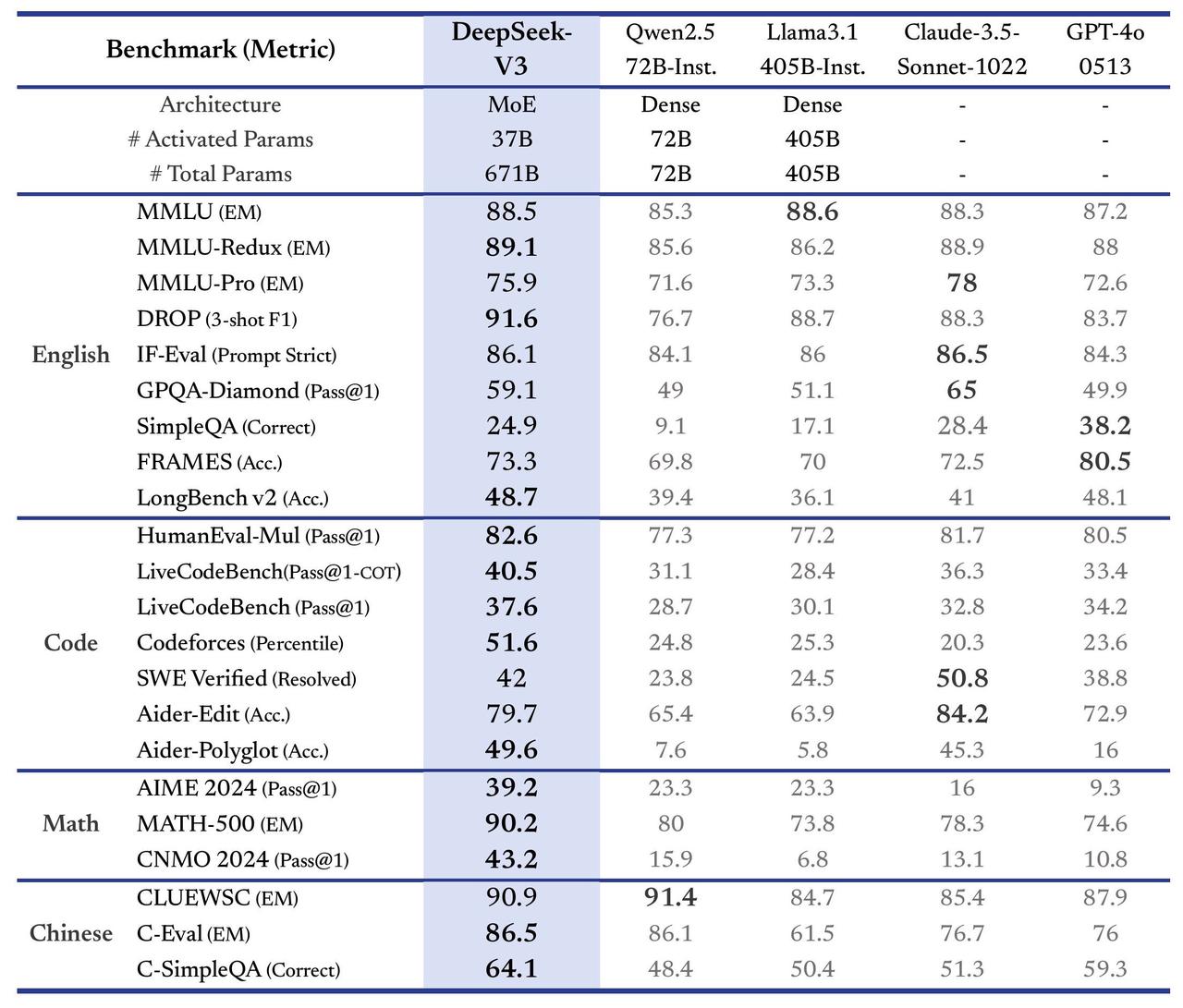
From this study, artificial thinking CoTs from DeepSeek R1 appear superior to human-expert CoTs in improving performance, albeit with a greater reasoning cost due to their longer length.
Fireworks AI Inference and Fine-Tuning Platform
DeepSeek R1 is available on the Fireworks AI platform. An easy to use distillation interface will quickly become part of FireOptimizer. If you require earlier gain access to, please contact us to explore options.
Conclusions
By including reasoning-based information through distillation, organizations can dramatically improve design efficiency without bearing the full problem of human-annotated datasets. DeepSeek R1's capability to produce long, premium reasoning chains makes it a powerful teacher model-showing that, in some cases, the device may just out-teach the human.













